
MGFN for Multimodal Scene Text Spotting
In recent years, scene text spotting approaches have evolved into a multimodal-based framework. Although previous studies have highlighted the crucial importance of the intrinsic synergy between visual and linguistic features, recent advances in multimodal-based methods typically adopt an implicit fusion strategy with single granularity features, which cannot fully exploit the prior contextual relationships embedded in visual and semantic information. We argue that directly integrating visual and semantic features is suboptimal because the multigranularity structure of scene text images is quite different from that of natural images. To address this, we introduce a novel model called the multigranularity visual semantic interactive fusion network (MGN-Net), which comprises a visual semantic multigranularity feature extraction network (VSMN) and a multigranularity graph fusion learning network (MGFN). The VSMN adaptively extracts multigranularity visual and semantic features from the text image, thereby enriching the textual contextual relations. In the MGFN, a cross-modal and cross-hierarchy graph is constructed to align features from different modalities for deep intra- and inter-fusion. This approach also alleviates the inflexibility of the sequential structure when dealing with images of irregularly curved objects. Furthermore, the cross-hierarchy semantic features are designed to facilitate the training of MGN-Net. Experimental results demonstrate that our model significantly outperforms previous state-of-the-art models. The code will be released in MGN-Net.
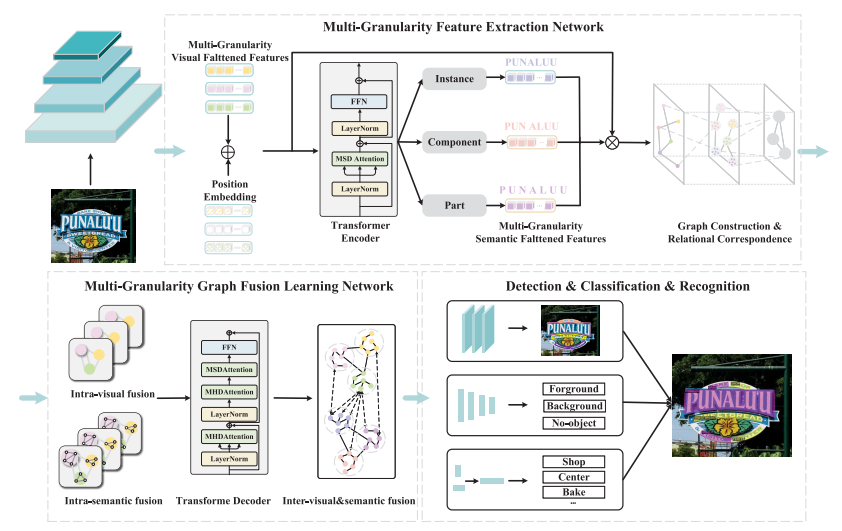
近年来,场景文本识别方法已 已发展成为一个基于多模态的框架。虽然以前的 研究强调了视觉和语言特征之间内在协同作用的关键重要性 协同作用的重要性,但最近基于多模态的 基于多模态的方法通常采用隐式融合策略,使用单一粒度特征 的隐式融合策略,这种策略无法充分 利用视觉和语义信息中蕴含的先验上下文关系。 语义信息。我们认为,直接整合视觉和语义特征 和语义特征是次优的,因为场景文本图像的多粒度 场景文本图像的多粒度结构与自然图像的多粒度结构截然不同。 自然图像不同。为了解决这个问题,我们引入了一种名为 多粒度视觉语义交互融合网络(MGN-Net),它包括一个视觉语义多粒度 特征提取网络(VSMN)和多粒度图 融合学习网络(MGFN)。VSMN 自适应地提取 多粒度视觉和语义特征。 图像,从而丰富文本上下文关系。在 MGFN 中,构建了一个跨模态和跨层级图 将不同模态的特征对齐,以实现深度的内部和相互融合。 融合。这种方法还能缓解 顺序结构的不灵活性。 大弯曲物体时的不灵活性。此外,跨层次语义 此外,交叉层次语义特征的设计还有助于 MGN-Net 的训练。 实验结果表明,我们的模型显著提高了图像的识别率。