
Visual Semantic Fusion
Since November 2023, research has been led on scene text detection and recognition methods based on a multimodal framework. The team has explored the intrinsic synergistic relationships between visual and linguistic features, addressing the issue that current multimodal approaches often use a single-granularity feature fusion strategy, which fails to fully leverage prior contextual information. To solve this problem, a Multi-Granularity Visual Semantic Interactive Fusion Network (MGN-Net) has been proposed, which includes: (1) a Visual Semantic Multi-Granularity Feature Extraction Network (VSMN); (2) a Multi-Granularity Graph Fusion Learning Network (MGFN).
In May 2024, this network was used to participate in the ICDAR 2024 competition (The International Conference on Document Analysis and Recognition, 2024).
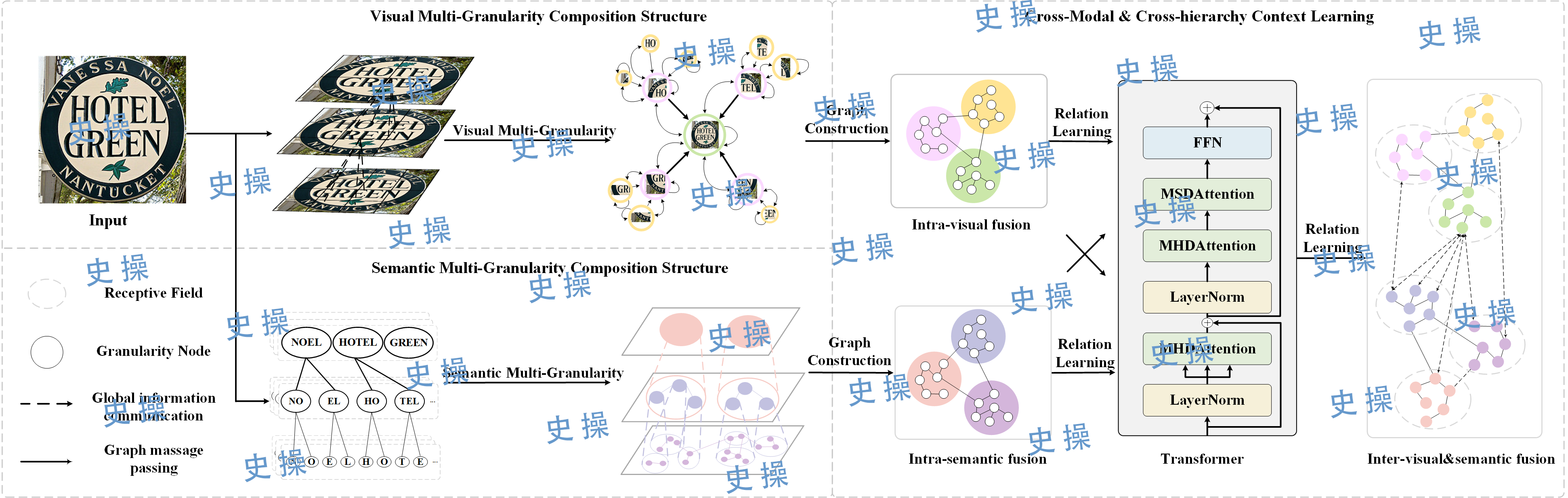
目前(自2023年11月起)正带领研究生研究基于多模态框架的场景文本检测和识别方法。团队研究了视觉和语言特征之间的内在协同规律,克服了目前多模态通常采用单一粒度特征的融合策略而无法充分利用先验上下文的问题。为了解决这个问题,我们提出了一种多粒度视觉语义交互融合网络(MGN-Net, Multi-Granularity Visual Semantic Interactive Fusion Network),其包含:(1)视觉语义多粒度特征提取网络(VSMN, Visual Semantic Multi-Granularity Feature Extraction Network); (2) 多粒度图融合学习网络(MGFN, Multi-Granularity Graph Fusion Learning Network)。
2024年5月,我们使用上图网络参加 ICDAR 2024 竞赛 (The International Conference on Document Analysis and Recognition, 2024)。